openGauss向量数据库基于鲲鹏BoostKit加速—亿级向量数据检索毫秒级召回
作者:王靖媛、吉文克、陈欢
{wangjingyuan8, jiwenke1, chenhuan67}@huawei.com
摘要
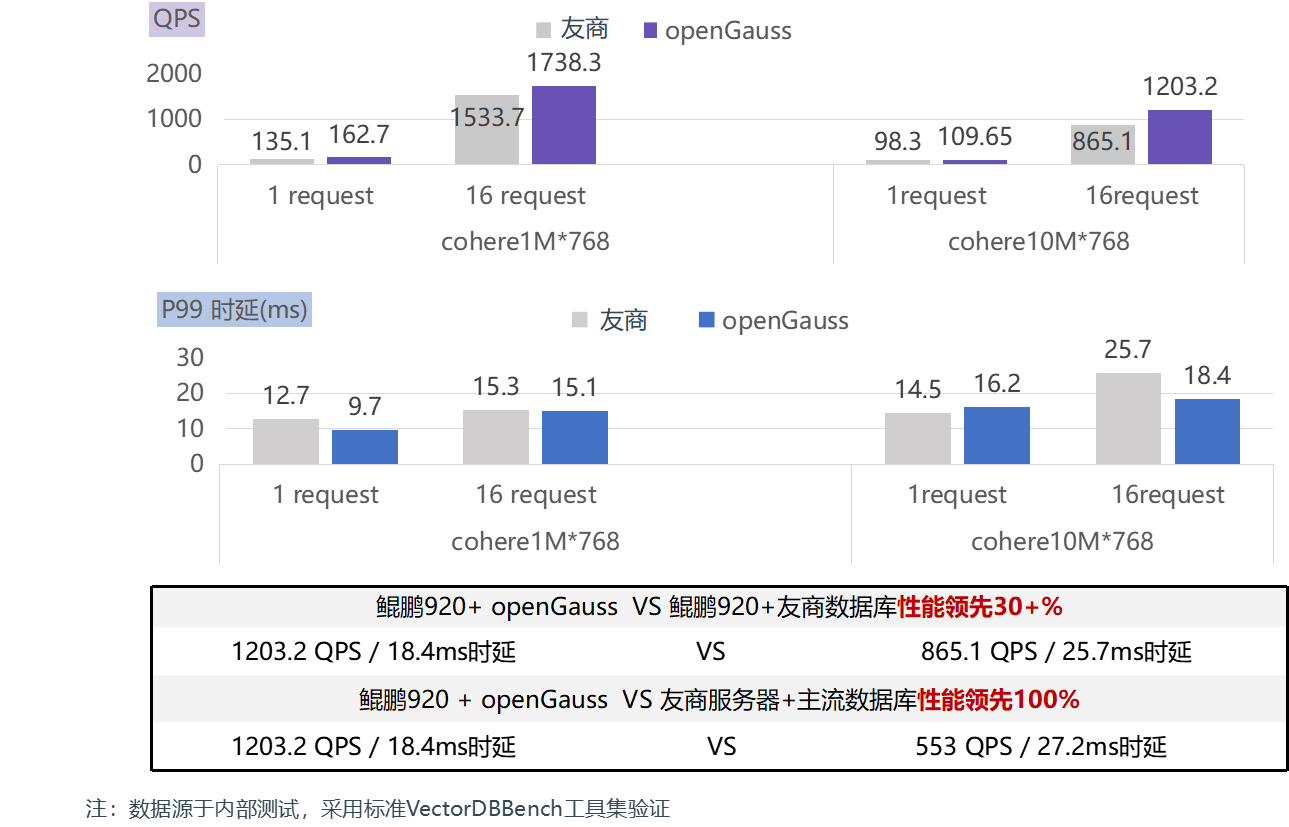
openGauss向量数据库继承传统数据库,支持以SQL进行向量数据的存储、检索和分析,构建高性能、大容量、高可用、高安全能力。其中,HNSWPQ(Hierarchical Navigable Small World with Product Quantization)索引通过创新的分层可导航小世界图和乘积量化技术,实现了海量高维向量的高效近似最近邻搜索。openGauss向量数据库通过加载鲲鹏BoostKit加速库将HNSW与PQ算法结合,亿级规模的向量可达到毫秒级检索,向量检索性能领先友商30%+。
面向企业知识库、市场研究、智能客服等典型应用场景,openGauss向量数据库作为RAG的“记忆中枢”可以实现高效存储和检索,而基于鲲鹏BoostKit加速库的HNSWPQ可以进一步提升近似检索性能。同时,HNSWPQ已在Dify、AnythingLLM等开源大语言模型开发平台内集成,降低企业使用openGauss向量数据库的技术门槛。
引言
向量数据库在AI时代专为向量而生,凭借优化的数据结构与算法,能快速存储、检索数据,高效完成相似性计算,其强大性能支撑推荐系统、大模型训练等应用。
在大规模向量数据检索场景中,高效性与准确性的平衡始终是核心挑战。层次化导航图(HNSW)索引以其分层图结构实现了近似最近邻(ANN)检索的快速导航,而乘积量化(PQ)算法则通过向量空间的分块聚类与压缩,显著降低了高维向量的存储与计算开销。OpenGauss向量数据库采用的 HNSWPQ 融合索引技术,巧妙结合了 HNSW 的图结构导航能力与 PQ 的量化压缩优势,在保证检索精度的同时大幅提升了大规模向量数据的检索效率。
方案设计
openGauss向量数据库深度结合鲲鹏硬件,通过量化压缩算法、Rerank精排、向量化指令加速等软硬协同技术,加速向量检索进程。
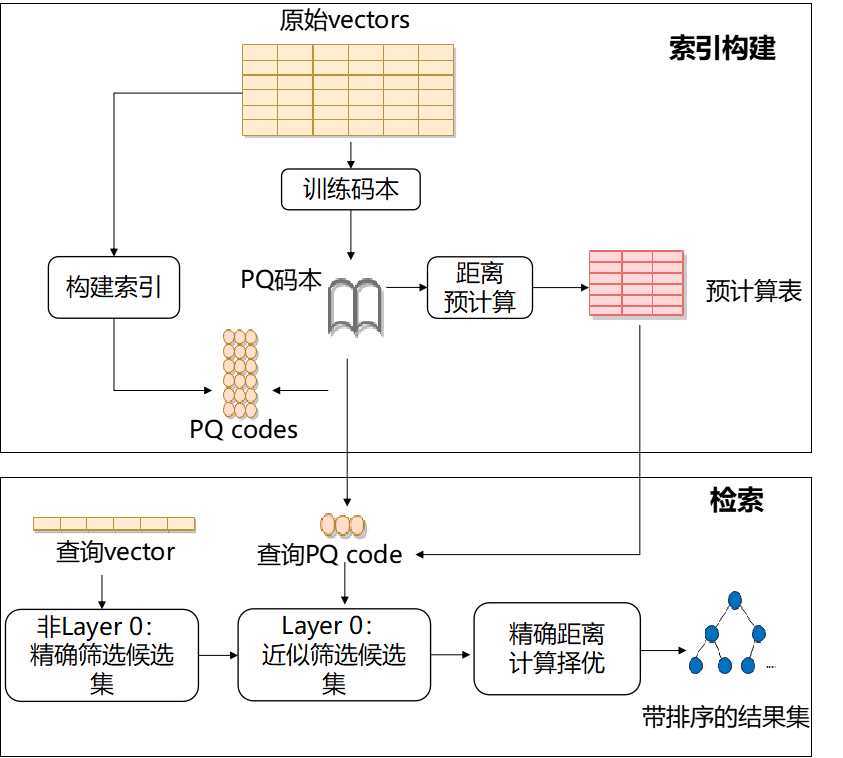
① 索引构建阶段
- 用原始vectors训练码本;
- 若PQ采用SDC距离计算,构建阶段可提前计算预计算表;
- 在HNSW图索引构建过程中,对vectors进行乘积量化,代替原始的高维向量。
② 检索阶段
- 0层以上的图采用FLAT求解器来计算查询vector与图中节点的距离;
- 第0层采用查询vector的乘积量化与PQ求解器的码本代替距离求解,极大提高计算效率;
- 精排:对采用PQ查表法获取的候选集进行精排,通过FLAT求解器更新候选集中元素的精确距离。
软硬协同 —— SIMD加速
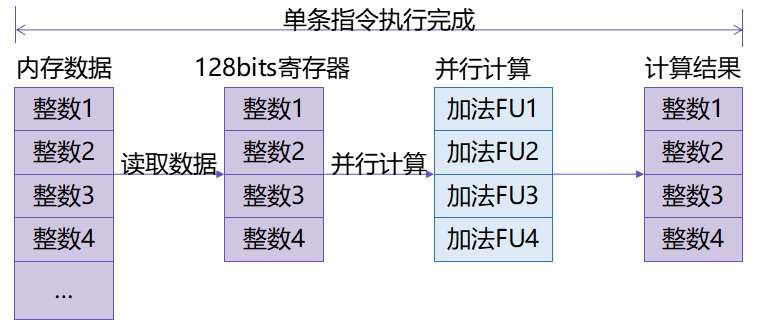
向量化指令集加速
- 通过鲲鹏NEON和SVE指令集对热点距离计算函数进行SIMD加速,支持128位计算,向量数据的并行处理可以充分利用鲲鹏多核算力,同时减少指令数量,降低访存次数,速度提升20%。
- 添加Prefetch指令加速数据访存。